Importar PDF Linkedin
Queremos facilitar seu cadastro.
Vamos tentar importar os dados do seu currículo PDF gerado pelo sistema do Linkedin.
Vamos lá, é bem fácil e rápido
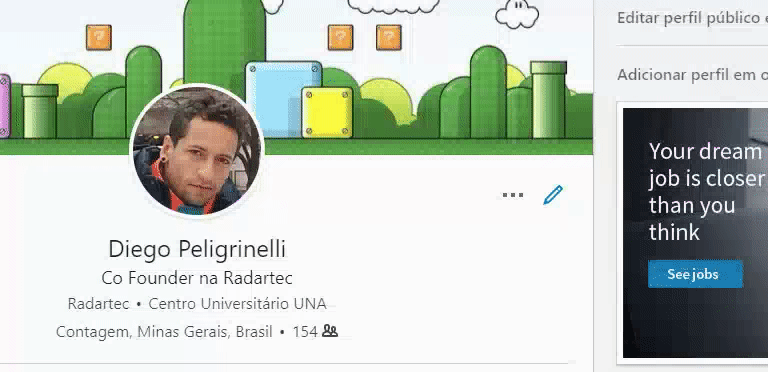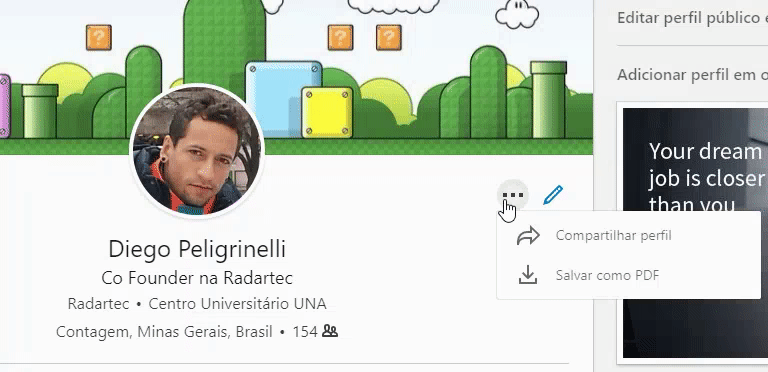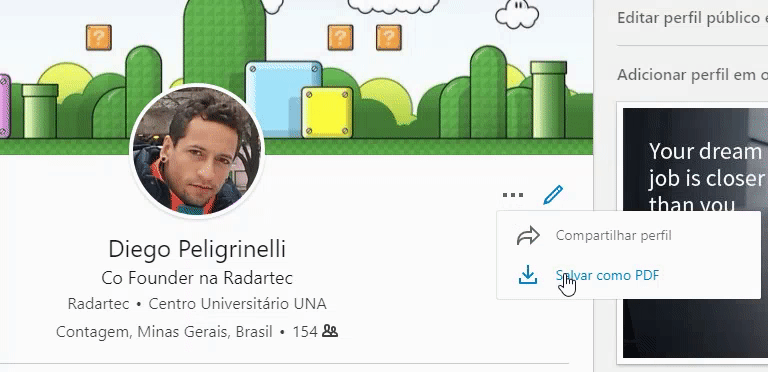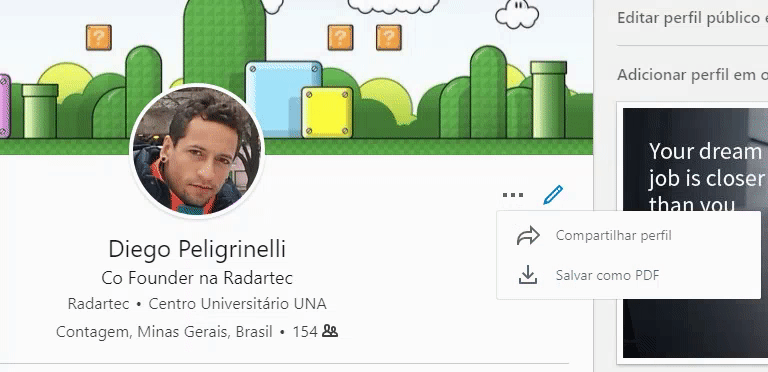
Acesse seu perfil do linkedin e salve o seu PDF, veja o exemplo ao lado.